class: center, middle, inverse, title-slide # Welcome ## Brief intro to R <br> 🙌 ### Ivan Castro <br /> VISN2 Center for Integrated Healthcare --- ## What we will cover today - Just the tip of the iceberg... - There's not enough time to cover everything - The content presented today is largely based on the [Data science in a Box](https://datasciencebox.org/content/explore/) materials - Given our roles, we will focus on: 1. How to start interacting with R 2. How to wrangle data in R -- ### Things we won't cover ...but I'll gladly help you with otherwise: - Advanced data wrangling - Detailed data visualization - Data modelling - Handling spatial data --- class: center, middle # What is Data Wrangling? --- class: center ## The data analysis cycle .center[ >Anyone who has ever taken wild-caught data through the full process of analysis knows that statistics, in the strict sense of fitting models and doing inference, is but one small part of the process. > > Bryan & Wickham ([2017](https://www.tandfonline.com/doi/full/10.1080/10618600.2017.1389743)) ] .center[  ] --- ## Who Am I? - Coordinator in Dr. Possemato's lab - Fairly new to CIH (less than a year) - Learned R (largely on my own) during graduate school - Trained in biostats - Enjoy the challenge of wrangling [messy data](https://brohrer.github.io/data_science_archetypes.html) .center[  ] --- class: right, middle ## Find me at... <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M443.683 4.529L27.818 196.418C-18.702 217.889-3.39 288 47.933 288H224v175.993c0 51.727 70.161 66.526 91.582 20.115L507.38 68.225c18.905-40.961-23.752-82.133-63.697-63.696z"/></svg> BHOC F204 <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M502.3 190.8c3.9-3.1 9.7-.2 9.7 4.7V400c0 26.5-21.5 48-48 48H48c-26.5 0-48-21.5-48-48V195.6c0-5 5.7-7.8 9.7-4.7 22.4 17.4 52.1 39.5 154.1 113.6 21.1 15.4 56.7 47.8 92.2 47.6 35.7.3 72-32.8 92.3-47.6 102-74.1 131.6-96.3 154-113.7zM256 320c23.2.4 56.6-29.2 73.4-41.4 132.7-96.3 142.8-104.7 173.4-128.7 5.8-4.5 9.2-11.5 9.2-18.9v-19c0-26.5-21.5-48-48-48H48C21.5 64 0 85.5 0 112v19c0 7.4 3.4 14.3 9.2 18.9 30.6 23.9 40.7 32.4 173.4 128.7 16.8 12.2 50.2 41.8 73.4 41.4z"/></svg> ivan.castro@va.gov <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M502.3 190.8c3.9-3.1 9.7-.2 9.7 4.7V400c0 26.5-21.5 48-48 48H48c-26.5 0-48-21.5-48-48V195.6c0-5 5.7-7.8 9.7-4.7 22.4 17.4 52.1 39.5 154.1 113.6 21.1 15.4 56.7 47.8 92.2 47.6 35.7.3 72-32.8 92.3-47.6 102-74.1 131.6-96.3 154-113.7zM256 320c23.2.4 56.6-29.2 73.4-41.4 132.7-96.3 142.8-104.7 173.4-128.7 5.8-4.5 9.2-11.5 9.2-18.9v-19c0-26.5-21.5-48-48-48H48C21.5 64 0 85.5 0 112v19c0 7.4 3.4 14.3 9.2 18.9 30.6 23.9 40.7 32.4 173.4 128.7 16.8 12.2 50.2 41.8 73.4 41.4z"/></svg> iecastro@syr.edu <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 496 512"><path d="M165.9 397.4c0 2-2.3 3.6-5.2 3.6-3.3.3-5.6-1.3-5.6-3.6 0-2 2.3-3.6 5.2-3.6 3-.3 5.6 1.3 5.6 3.6zm-31.1-4.5c-.7 2 1.3 4.3 4.3 4.9 2.6 1 5.6 0 6.2-2s-1.3-4.3-4.3-5.2c-2.6-.7-5.5.3-6.2 2.3zm44.2-1.7c-2.9.7-4.9 2.6-4.6 4.9.3 2 2.9 3.3 5.9 2.6 2.9-.7 4.9-2.6 4.6-4.6-.3-1.9-3-3.2-5.9-2.9zM244.8 8C106.1 8 0 113.3 0 252c0 110.9 69.8 205.8 169.5 239.2 12.8 2.3 17.3-5.6 17.3-12.1 0-6.2-.3-40.4-.3-61.4 0 0-70 15-84.7-29.8 0 0-11.4-29.1-27.8-36.6 0 0-22.9-15.7 1.6-15.4 0 0 24.9 2 38.6 25.8 21.9 38.6 58.6 27.5 72.9 20.9 2.3-16 8.8-27.1 16-33.7-55.9-6.2-112.3-14.3-112.3-110.5 0-27.5 7.6-41.3 23.6-58.9-2.6-6.5-11.1-33.3 2.6-67.9 20.9-6.5 69 27 69 27 20-5.6 41.5-8.5 62.8-8.5s42.8 2.9 62.8 8.5c0 0 48.1-33.6 69-27 13.7 34.7 5.2 61.4 2.6 67.9 16 17.7 25.8 31.5 25.8 58.9 0 96.5-58.9 104.2-114.8 110.5 9.2 7.9 17 22.9 17 46.4 0 33.7-.3 75.4-.3 83.6 0 6.5 4.6 14.4 17.3 12.1C428.2 457.8 496 362.9 496 252 496 113.3 383.5 8 244.8 8zM97.2 352.9c-1.3 1-1 3.3.7 5.2 1.6 1.6 3.9 2.3 5.2 1 1.3-1 1-3.3-.7-5.2-1.6-1.6-3.9-2.3-5.2-1zm-10.8-8.1c-.7 1.3.3 2.9 2.3 3.9 1.6 1 3.6.7 4.3-.7.7-1.3-.3-2.9-2.3-3.9-2-.6-3.6-.3-4.3.7zm32.4 35.6c-1.6 1.3-1 4.3 1.3 6.2 2.3 2.3 5.2 2.6 6.5 1 1.3-1.3.7-4.3-1.3-6.2-2.2-2.3-5.2-2.6-6.5-1zm-11.4-14.7c-1.6 1-1.6 3.6 0 5.9 1.6 2.3 4.3 3.3 5.6 2.3 1.6-1.3 1.6-3.9 0-6.2-1.4-2.3-4-3.3-5.6-2z"/></svg> [iecastro](https://github.com/iecastro) <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 448 512"><path d="M416 32H31.9C14.3 32 0 46.5 0 64.3v383.4C0 465.5 14.3 480 31.9 480H416c17.6 0 32-14.5 32-32.3V64.3c0-17.8-14.4-32.3-32-32.3zM135.4 416H69V202.2h66.5V416zm-33.2-243c-21.3 0-38.5-17.3-38.5-38.5S80.9 96 102.2 96c21.2 0 38.5 17.3 38.5 38.5 0 21.3-17.2 38.5-38.5 38.5zm282.1 243h-66.4V312c0-24.8-.5-56.7-34.5-56.7-34.6 0-39.9 27-39.9 54.9V416h-66.4V202.2h63.7v29.2h.9c8.9-16.8 30.6-34.5 62.9-34.5 67.2 0 79.7 44.3 79.7 101.9V416z"/></svg> [iecastro](https://www.linkedin.com/in/iecastro) --- class: title-slide # Meet the toolkit <br> ⚒ --- ## Toolkit  - Scriptability `\(\rightarrow\)` R - Literate programming (code, narrative, output in one place) `\(\rightarrow\)` R Markdown - Version control `\(\rightarrow\)` Git / GitHub --- class: center, middle # Reproducible data wrangling and analysis --- ## Reproducibility checklist .question[ What does it mean for a data analysis to be "reproducible"? ] -- Near-term goals: - Are the tables and figures reproducible from the code and data? - Does the code actually do what you think it does? - In addition to what was done, is it clear **why** it was done? (e.g., how were parameter settings chosen?) Long-term goals: - Can the code be used for other data? - Can you extend the code to do other things? --- ## From manual tasking... <img src="img/manual-datapull.png" width="550" height="500" style="display: block; margin: auto;" /> --- ## ... to reproducible code <img src="img/script-datapull.png" width="600" height="500" style="display: block; margin: auto;" /> --- ## Reproducible plots 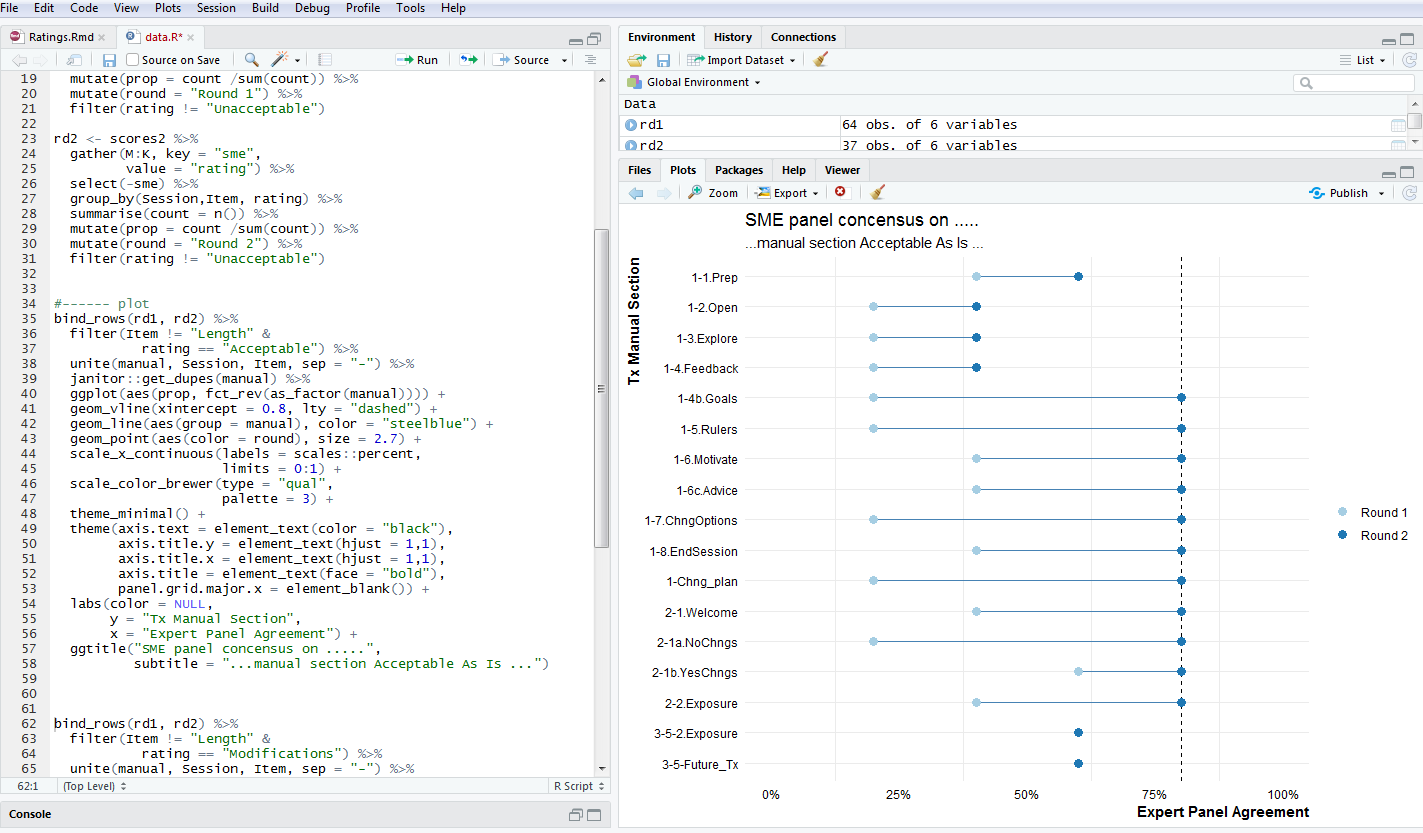 --- class: center, middle # R and RStudio --- ## What is R - R is a statistical programming language - But why learn programming? -- >You must use a computer to do data science; you cannot do it in your head, or with pencil and paper. > >Hadley Wickham > .center[  ] - Don't be discouraged by the word _programming_; R is first and foremost for data analysis .footnote[ ➥ Source: [R for Data Science](https://r4ds.had.co.nz/) ] --- ## What is RStudio? - RStudio is a convenient interface for R (an integreated development environment, IDE) - At its simplest:<sup>➥</sup> - R is like a car’s engine - RStudio is like a car’s dashboard <img src="img/engine-dashboard.png" style="display: block; margin: auto;" /> .footnote[ ➥ Source: [Modern Dive](https://moderndive.com/) ] --- ## <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 640 512"><path d="M537.6 226.6c4.1-10.7 6.4-22.4 6.4-34.6 0-53-43-96-96-96-19.7 0-38.1 6-53.3 16.2C367 64.2 315.3 32 256 32c-88.4 0-160 71.6-160 160 0 2.7.1 5.4.2 8.1C40.2 219.8 0 273.2 0 336c0 79.5 64.5 144 144 144h368c70.7 0 128-57.3 128-128 0-61.9-44-113.6-102.4-125.4z"/></svg> Let's take a tour - R / RStudio Follow this link and log in with your google account: https://rstudio.cloud/project/395951 -- Concepts introduced: - Console - Using R as a calculator - Environment - Loading and viewing a data frame - Accessing a variable in a data frame - R functions --- ## R essentials A short list (for now): - Functions are (most often) verbs, followed by what they will be applied to in parantheses: ```r do_this(to_this) do_that(to_this, to_that, with_those) ``` -- - Columns (variables) in data frames are accessed with `$`: ```r dataframe$var_name ``` -- - Packages are installed with the `install.packages` function and loaded with the `library` function, once per session: ```r install.packages("package_name") library(package_name) ``` -- - For this project we'll need the following packages: ```r install.packages(c("tidyverse", "devtools", "datasauRus", "fivethirtyeight", "janitor", "DT")) ``` --- ## tidyverse .pull-left[  ] .pull-right[ .center[ [tidyverse.org](https://www.tidyverse.org/) ] - The tidyverse is an opinionated collection of R packages designed for data science. - All packages share an underlying philosophy and a common grammar. ] --- class: center, middle # R Markdown --- ## R Markdown - Fully reproducible reports -- each time you knit the analysis is ran from the beginning - Simple markdown syntax for text - Code goes in chunks, defined by three backticks, narrative goes outside of chunks --- ## <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 640 512"><path d="M512 64v256H128V64h384m16-64H112C85.5 0 64 21.5 64 48v288c0 26.5 21.5 48 48 48h416c26.5 0 48-21.5 48-48V48c0-26.5-21.5-48-48-48zm100 416H389.5c-3 0-5.5 2.1-5.9 5.1C381.2 436.3 368 448 352 448h-64c-16 0-29.2-11.7-31.6-26.9-.5-2.9-3-5.1-5.9-5.1H12c-6.6 0-12 5.4-12 12v36c0 26.5 21.5 48 48 48h544c26.5 0 48-21.5 48-48v-36c0-6.6-5.4-12-12-12z"/></svg> Let's take a tour - R Markdown Go to RStudio Cloud and open the application exercise Bechdel. ~/appex/ae-bechdel.Rmd Concepts introduced: - Knitting documents - R Markdown and (some) R syntax --- ## <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 640 512"><path d="M278.9 511.5l-61-17.7c-6.4-1.8-10-8.5-8.2-14.9L346.2 8.7c1.8-6.4 8.5-10 14.9-8.2l61 17.7c6.4 1.8 10 8.5 8.2 14.9L293.8 503.3c-1.9 6.4-8.5 10.1-14.9 8.2zm-114-112.2l43.5-46.4c4.6-4.9 4.3-12.7-.8-17.2L117 256l90.6-79.7c5.1-4.5 5.5-12.3.8-17.2l-43.5-46.4c-4.5-4.8-12.1-5.1-17-.5L3.8 247.2c-5.1 4.7-5.1 12.8 0 17.5l144.1 135.1c4.9 4.6 12.5 4.4 17-.5zm327.2.6l144.1-135.1c5.1-4.7 5.1-12.8 0-17.5L492.1 112.1c-4.8-4.5-12.4-4.3-17 .5L431.6 159c-4.6 4.9-4.3 12.7.8 17.2L523 256l-90.6 79.7c-5.1 4.5-5.5 12.3-.8 17.2l43.5 46.4c4.5 4.9 12.1 5.1 17 .6z"/></svg> Bechdel Test .question[ What is the Bechdel test? ] -- The Bechdel test asks whether a work of fiction features at least two women who talk to each other about something other than a man, and there must be two women named characters. -- - Knit the R Markdown document. --- ## Other things you can make in R Markdown <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 384 512"><path d="M193.7 271.2c8.8 0 15.5 2.7 20.3 8.1 9.6 10.9 9.8 32.7-.2 44.1-4.9 5.6-11.9 8.5-21.1 8.5h-26.9v-60.7h27.9zM377 105L279 7c-4.5-4.5-10.6-7-17-7h-6v128h128v-6.1c0-6.3-2.5-12.4-7-16.9zm-153 31V0H24C10.7 0 0 10.7 0 24v464c0 13.3 10.7 24 24 24h336c13.3 0 24-10.7 24-24V160H248c-13.2 0-24-10.8-24-24zm53 165.2c0 90.3-88.8 77.6-111.1 77.6V436c0 6.6-5.4 12-12 12h-30.8c-6.6 0-12-5.4-12-12V236.2c0-6.6 5.4-12 12-12h81c44.5 0 72.9 32.8 72.9 77z"/></svg> This presentation was written in R Markdown <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 384 512"><path d="M224 136V0H24C10.7 0 0 10.7 0 24v464c0 13.3 10.7 24 24 24h336c13.3 0 24-10.7 24-24V160H248c-13.2 0-24-10.8-24-24zm160-14.1v6.1H256V0h6.1c6.4 0 12.5 2.5 17 7l97.9 98c4.5 4.5 7 10.6 7 16.9z"/></svg> [HTML resume](https://iecastro.github.io/web-resume) <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 512 512"><path d="M326.612 185.391c59.747 59.809 58.927 155.698.36 214.59-.11.12-.24.25-.36.37l-67.2 67.2c-59.27 59.27-155.699 59.262-214.96 0-59.27-59.26-59.27-155.7 0-214.96l37.106-37.106c9.84-9.84 26.786-3.3 27.294 10.606.648 17.722 3.826 35.527 9.69 52.721 1.986 5.822.567 12.262-3.783 16.612l-13.087 13.087c-28.026 28.026-28.905 73.66-1.155 101.96 28.024 28.579 74.086 28.749 102.325.51l67.2-67.19c28.191-28.191 28.073-73.757 0-101.83-3.701-3.694-7.429-6.564-10.341-8.569a16.037 16.037 0 0 1-6.947-12.606c-.396-10.567 3.348-21.456 11.698-29.806l21.054-21.055c5.521-5.521 14.182-6.199 20.584-1.731a152.482 152.482 0 0 1 20.522 17.197zM467.547 44.449c-59.261-59.262-155.69-59.27-214.96 0l-67.2 67.2c-.12.12-.25.25-.36.37-58.566 58.892-59.387 154.781.36 214.59a152.454 152.454 0 0 0 20.521 17.196c6.402 4.468 15.064 3.789 20.584-1.731l21.054-21.055c8.35-8.35 12.094-19.239 11.698-29.806a16.037 16.037 0 0 0-6.947-12.606c-2.912-2.005-6.64-4.875-10.341-8.569-28.073-28.073-28.191-73.639 0-101.83l67.2-67.19c28.239-28.239 74.3-28.069 102.325.51 27.75 28.3 26.872 73.934-1.155 101.96l-13.087 13.087c-4.35 4.35-5.769 10.79-3.783 16.612 5.864 17.194 9.042 34.999 9.69 52.721.509 13.906 17.454 20.446 27.294 10.606l37.106-37.106c59.271-59.259 59.271-155.699.001-214.959z"/></svg> [Blog / Website](https://iecastro.github.io/blog/2018-09-13/ndi-dist-prof.html) -- ... ok, enough self promotion 👨💼 --- ## R Markdown help .pull-left[ .center[ [R Markdown cheat sheet](https://github.com/rstudio/cheatsheets/raw/master/rmarkdown-2.0.pdf) ]  ] .pull-right[ .center[ Markdown Quick Reference `Help -> Markdown Quick Reference` ]  ] --- ## Workspaces Remember this, and expect it to bite you a few times as you're learning to work with R Markdown: The workspace of your R Markdown document is separate from the Console! - Run the following in the console ```r x <- 2 x * 3 ``` .question[ All looks good, eh? ] -- - Then, add the following chunk in your R Markdown document and knit it ```r x * 3 ``` .question[ What happens? Why the error? ] --- class: center, middle # Git and GitHub --- ## Version control - GitHub as a platform for collaboration - It's actually designed for version control --- ## Versioning <img src="img/lego-steps.png" width="1200" style="display: block; margin: auto;" /> --- ## Versioning with human readable messages <img src="img/lego-steps-commit-messages.png" width="1200" style="display: block; margin: auto;" /> --- ## Why do we need version control? <img src="img/phd_comics_vc.gif" style="display: block; margin: auto;" /> --- # Git and GitHub tips - Git is a version control system -- like “Track Changes” features from Microsoft Word on steroids. GitHub is the home for your Git-based projects on the internet -- like DropBox but much, much better). - __This is outside the scope of this workshop.__ - There is a great resource for working with git and R: [happygitwithr.com](http://happygitwithr.com/). --- class: title-slide # Tidy data and data wrangling <br> 🔧 --- class: center, middle name: tidy # Tidy data --- ## Tidy data >Happy families are all alike; every unhappy family is unhappy in its own way. > >Leo Tolstoy > -- .pull-left[ **Characteristics of tidy data:** 😄 - Each variable forms a column. - Each observation forms a row. - Each type of observational unit forms a table. ] .pull-right[ **Characteristics of untidy data:** 😦 !@#$%^&*() ] --  .footnote[ ➥ Source: [R for Data Science](https://r4ds.had.co.nz/) ] --- class: middle >Like families, tidy datasets are all alike but every messy dataset is messy in its own way. > >Hadley Wickham --- ## Summary tables .question[ Is each of the following a dataset or a summary table? ] .small[ .pull-left[ ``` ## # A tibble: 87 x 3 ## name height mass ## <chr> <int> <dbl> ## 1 Luke Skywalker 172 77 ## 2 C-3PO 167 75 ## 3 R2-D2 96 32 ## 4 Darth Vader 202 136 ## 5 Leia Organa 150 49 ## 6 Owen Lars 178 120 ## 7 Beru Whitesun lars 165 75 ## 8 R5-D4 97 32 ## 9 Biggs Darklighter 183 84 ## 10 Obi-Wan Kenobi 182 77 ## # … with 77 more rows ``` ] .pull-right[ ``` ## # A tibble: 5 x 2 ## gender avg_height ## <chr> <dbl> ## 1 female 165. ## 2 hermaphrodite 175 ## 3 male 179. ## 4 none 200 ## 5 <NA> 120 ``` ] ] --- class: center, middle # Pipes --- ## Where does the name come from? The pipe operator is implemented in the package **magrittr**, it's pronounced "and then". .pull-left[  ] .pull-right[  ] .footnote[ ➥ Vignette: [magrittr](https://cran.r-project.org/web/packages/magrittr/vignettes/magrittr.html) ] --- ## Review: How does a pipe work? - You can think about the following sequence of actions - find key, unlock car, start car, drive to school, park. -- - Expressed as a set of nested functions in R pseudocode this would look like: ```r park(drive(start_car(find("keys")), to = "campus")) ``` -- - Writing it out using pipes give it a more natural (and easier to read) structure: ```r find("keys") %>% start_car() %>% drive(to = "campus") %>% park() ``` --- ## What about other arguments? To send results to a function argument other than first one or to use the previous result for multiple arguments, use `.`: ```r starwars %>% filter(species == "Human") %>% lm(mass ~ height, data = .) ``` ``` ## ## Call: ## lm(formula = mass ~ height, data = .) ## ## Coefficients: ## (Intercept) height ## -116.58 1.11 ``` --- class: center, middle name: wrangle # Data wrangling --- ## Bike crashes in NC 2007 - 2014 The dataset is in the **dsbox** package: - github packages require special install commands - the **remotes** package is automatically installed with **devtools** ```r remotes::install_github("rstudio-education/dsbox") library(dsbox) ncbikecrash ``` --- ## Variables View the names of variables via ```r names(ncbikecrash) ``` ``` ## [1] "object_id" "city" "county" ## [4] "region" "development" "locality" ## [7] "on_road" "rural_urban" "speed_limit" ## [10] "traffic_control" "weather" "workzone" ## [13] "bike_age" "bike_age_group" "bike_alcohol" ## [16] "bike_alcohol_drugs" "bike_direction" "bike_injury" ## [19] "bike_position" "bike_race" "bike_sex" ## [22] "driver_age" "driver_age_group" "driver_alcohol" ## [25] "driver_alcohol_drugs" "driver_est_speed" "driver_injury" ## [28] "driver_race" "driver_sex" "driver_vehicle_type" ## [31] "crash_alcohol" "crash_date" "crash_day" ## [34] "crash_group" "crash_hour" "crash_location" ## [37] "crash_month" "crash_severity" "crash_time" ## [40] "crash_type" "crash_year" "ambulance_req" ## [43] "hit_run" "light_condition" "road_character" ## [46] "road_class" "road_condition" "road_configuration" ## [49] "road_defects" "road_feature" "road_surface" ## [52] "num_bikes_ai" "num_bikes_bi" "num_bikes_ci" ## [55] "num_bikes_ki" "num_bikes_no" "num_bikes_to" ## [58] "num_bikes_ui" "num_lanes" "num_units" ## [61] "distance_mi_from" "frm_road" "rte_invd_cd" ## [64] "towrd_road" "geo_point" "geo_shape" ``` and see detailed descriptions with `?ncbikecrash`. --- ## Viewing your data - In the Environment, after loading with `data(ncbikecrash)`, and click on the name of the data frame to view it in the data viewer - Use the `glimpse` function to take a peek -- ```r glimpse(ncbikecrash) ``` ``` ## Observations: 7,467 ## Variables: 66 ## $ object_id <int> 1686, 1674, 1673, 1687, 1653, 1665, 1642, 1… ## $ city <chr> "None - Rural Crash", "Henderson", "None - … ## $ county <chr> "Wayne", "Vance", "Lincoln", "Columbus", "N… ## $ region <chr> "Coastal", "Piedmont", "Piedmont", "Coastal… ## $ development <chr> "Farms, Woods, Pastures", "Residential", "F… ## $ locality <chr> "Rural (<30% Developed)", "Mixed (30% To 70… ## $ on_road <chr> "SR 1915", "NICHOLAS ST", "US 321", "W BURK… ## $ rural_urban <chr> "Rural", "Urban", "Rural", "Urban", "Urban"… ## $ speed_limit <chr> "50 - 55 MPH", "30 - 35 MPH", "50 - 55 M… ## $ traffic_control <chr> "No Control Present", "Stop Sign", "Double … ## $ weather <chr> "Clear", "Clear", "Clear", "Rain", "Clear",… ## $ workzone <chr> "No", "No", "No", "No", "No", "No", "No", "… ## $ bike_age <chr> "52", "66", "33", "52", "22", "15", "41", "… ## $ bike_age_group <chr> "50-59", "60-69", "30-39", "50-59", "20-24"… ## $ bike_alcohol <chr> "No", "No", "No", "Yes", "No", "No", "No", … ## $ bike_alcohol_drugs <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… ## $ bike_direction <chr> "With Traffic", "With Traffic", "With Traff… ## $ bike_injury <chr> "B: Evident Injury", "C: Possible Injury", … ## $ bike_position <chr> "Bike Lane / Paved Shoulder", "Travel Lane"… ## $ bike_race <chr> "Black", "Black", "White", "Black", "White"… ## $ bike_sex <chr> "Male", "Male", "Male", "Male", "Female", "… ## $ driver_age <chr> "34", NA, "37", "55", "25", "17", NA, "50",… ## $ driver_age_group <chr> "30-39", NA, "30-39", "50-59", "25-29", "0-… ## $ driver_alcohol <chr> "No", "Missing", "No", "No", "No", "No", "M… ## $ driver_alcohol_drugs <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… ## $ driver_est_speed <chr> "51-55 mph", "6-10 mph", "41-45 mph", "11-1… ## $ driver_injury <chr> "O: No Injury", "Unknown Injury", "O: No In… ## $ driver_race <chr> "White", "Unknown/Missing", "Hispanic", "Bl… ## $ driver_sex <chr> "Male", NA, "Female", "Male", "Male", "Fema… ## $ driver_vehicle_type <chr> "Single Unit Truck (2-Axle, 6-Tire)", NA, "… ## $ crash_alcohol <chr> "No", "No", "No", "Yes", "No", "No", "No", … ## $ crash_date <chr> "11DEC2013", "20NOV2013", "03NOV2013", "14D… ## $ crash_day <chr> "Wednesday", "Wednesday", "Sunday", "Saturd… ## $ crash_group <chr> "Motorist Overtaking Bicyclist", "Bicyclist… ## $ crash_hour <int> 6, 20, 18, 18, 13, 17, 17, 7, 15, 2, 12, 22… ## $ crash_location <chr> "Non-Intersection", "Intersection", "Non-In… ## $ crash_month <chr> "December", "November", "November", "Decemb… ## $ crash_severity <chr> "B: Evident Injury", "C: Possible Injury", … ## $ crash_time <drtn> 06:10:00, 20:41:00, 18:05:00, 18:34:00, 13… ## $ crash_type <chr> "Motorist Overtaking - Undetected Bicyclist… ## $ crash_year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2… ## $ ambulance_req <chr> "Yes", "No", "Yes", "Yes", "Yes", "Yes", "Y… ## $ hit_run <chr> "No", "Yes", "No", "No", "No", "No", "Yes",… ## $ light_condition <chr> "Dark - Roadway Not Lighted", NA, "Dark - R… ## $ road_character <chr> "Straight - Level", "Straight - Level", "St… ## $ road_class <chr> "State Secondary Route", "Local Street", "U… ## $ road_condition <chr> "Dry", "Dry", "Dry", "Water (Standing, Movi… ## $ road_configuration <chr> "Two-Way, Not Divided", "Two-Way, Divided, … ## $ road_defects <chr> "None", NA, "None", "None", "None", "None",… ## $ road_feature <chr> "No Special Feature", "T-Intersection", "No… ## $ road_surface <chr> "Coarse Asphalt", "Smooth Asphalt", "Smooth… ## $ num_bikes_ai <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_bi <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_ci <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_ki <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_no <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_to <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_bikes_ui <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ num_lanes <chr> "2 lanes", "2 lanes", "2 lanes", "1 lane", … ## $ num_units <int> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2… ## $ distance_mi_from <chr> "0", "0", "0", "0", "0", "0", "0", "0", "0"… ## $ frm_road <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… ## $ rte_invd_cd <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0… ## $ towrd_road <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,… ## $ geo_point <chr> "35.3336070056, -77.9955023901", "36.315187… ## $ geo_shape <chr> "{\"type\": \"Point\", \"coordinates\": [-7… ``` --- ## A Grammar of Data Manipulation **dplyr** is based on the concepts of functions as verbs that manipulate data frames. .pull-left[  ] .pull-right[ .midi[ - `filter`: pick rows matching criteria - `slice`: pick rows using index(es) - `select`: pick columns by name - `pull`: grab a column as a vector - `arrange`: reorder rows - `mutate`: add new variables - `distinct`: filter for unique rows - `sample_n` / `sample_frac`: randomly sample rows - `summarise`: reduce variables to values - ... (many more) ] ] --- ## **dplyr** rules for functions - First argument is *always* a data frame - Subsequent arguments say what to do with that data frame - Always return a data frame - Don't modify in place --- ## A note on piping and layering - The `%>%` operator in **dplyr** functions is called the pipe operator. This means you "pipe" the output of the previous line of code as the first input of the next line of code. - The `+` operator in **ggplot2** functions is used for "layering". This means you create the plot in layers, separated by `+`. --- ## `filter` to select a subset of rows for crashes in Durham County ```r ncbikecrash %>% * filter(county == "Durham") ``` ``` ## # A tibble: 340 x 66 ## object_id city county region development locality on_road rural_urban ## <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 2452 Durh… Durham Piedm… Residential Urban (… <NA> Urban ## 2 2441 Durh… Durham Piedm… Commercial Urban (… <NA> Urban ## 3 2466 Durh… Durham Piedm… Commercial Urban (… <NA> Urban ## 4 549 Durh… Durham Piedm… Residential Urban (… PARK A… Urban ## 5 598 Durh… Durham Piedm… Residential Urban (… BELT S… Urban ## 6 603 Durh… Durham Piedm… Residential Urban (… HINSON… Urban ## 7 3974 Durh… Durham Piedm… Commercial Urban (… <NA> Urban ## 8 7134 Durh… Durham Piedm… Commercial Urban (… <NA> Urban ## 9 1670 Durh… Durham Piedm… Commercial Urban (… INFINI… Urban ## 10 1773 Durh… Durham Piedm… Residential Urban (… <NA> Urban ## # … with 330 more rows, and 58 more variables: speed_limit <chr>, ## # traffic_control <chr>, weather <chr>, workzone <chr>, bike_age <chr>, ## # bike_age_group <chr>, bike_alcohol <chr>, bike_alcohol_drugs <chr>, ## # bike_direction <chr>, bike_injury <chr>, bike_position <chr>, ## # bike_race <chr>, bike_sex <chr>, driver_age <chr>, ## # driver_age_group <chr>, driver_alcohol <chr>, ## # driver_alcohol_drugs <chr>, driver_est_speed <chr>, ## # driver_injury <chr>, driver_race <chr>, driver_sex <chr>, ## # driver_vehicle_type <chr>, crash_alcohol <chr>, crash_date <chr>, ## # crash_day <chr>, crash_group <chr>, crash_hour <int>, ## # crash_location <chr>, crash_month <chr>, crash_severity <chr>, ## # crash_time <drtn>, crash_type <chr>, crash_year <int>, ## # ambulance_req <chr>, hit_run <chr>, light_condition <chr>, ## # road_character <chr>, road_class <chr>, road_condition <chr>, ## # road_configuration <chr>, road_defects <chr>, road_feature <chr>, ## # road_surface <chr>, num_bikes_ai <int>, num_bikes_bi <int>, ## # num_bikes_ci <int>, num_bikes_ki <int>, num_bikes_no <int>, ## # num_bikes_to <int>, num_bikes_ui <int>, num_lanes <chr>, ## # num_units <int>, distance_mi_from <chr>, frm_road <chr>, ## # rte_invd_cd <int>, towrd_road <chr>, geo_point <chr>, geo_shape <chr> ``` --- ## `filter` for many conditions at once for crashes in Durham County where biker was 0-5 years old ```r ncbikecrash %>% filter(county == "Durham", bike_age_group == "0-5") ``` ``` ## # A tibble: 4 x 66 ## object_id city county region development locality on_road rural_urban ## <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 4062 Durh… Durham Piedm… Residential Urban (… <NA> Urban ## 2 414 Durh… Durham Piedm… Residential Urban (… PVA 90… Urban ## 3 3016 Durh… Durham Piedm… Residential Urban (… <NA> Urban ## 4 1383 Durh… Durham Piedm… Residential Urban (… PVA 62… Urban ## # … with 58 more variables: speed_limit <chr>, traffic_control <chr>, ## # weather <chr>, workzone <chr>, bike_age <chr>, bike_age_group <chr>, ## # bike_alcohol <chr>, bike_alcohol_drugs <chr>, bike_direction <chr>, ## # bike_injury <chr>, bike_position <chr>, bike_race <chr>, ## # bike_sex <chr>, driver_age <chr>, driver_age_group <chr>, ## # driver_alcohol <chr>, driver_alcohol_drugs <chr>, ## # driver_est_speed <chr>, driver_injury <chr>, driver_race <chr>, ## # driver_sex <chr>, driver_vehicle_type <chr>, crash_alcohol <chr>, ## # crash_date <chr>, crash_day <chr>, crash_group <chr>, ## # crash_hour <int>, crash_location <chr>, crash_month <chr>, ## # crash_severity <chr>, crash_time <drtn>, crash_type <chr>, ## # crash_year <int>, ambulance_req <chr>, hit_run <chr>, ## # light_condition <chr>, road_character <chr>, road_class <chr>, ## # road_condition <chr>, road_configuration <chr>, road_defects <chr>, ## # road_feature <chr>, road_surface <chr>, num_bikes_ai <int>, ## # num_bikes_bi <int>, num_bikes_ci <int>, num_bikes_ki <int>, ## # num_bikes_no <int>, num_bikes_to <int>, num_bikes_ui <int>, ## # num_lanes <chr>, num_units <int>, distance_mi_from <chr>, ## # frm_road <chr>, rte_invd_cd <int>, towrd_road <chr>, geo_point <chr>, ## # geo_shape <chr> ``` --- ## Logical operators in R operator | definition || operator | definition ------------|------------------------------||--------------|---------------- `<` | less than ||`x` | `y` | `x` OR `y` `<=` | less than or equal to ||`is.na(x)` | test if `x` is `NA` `>` | greater than ||`!is.na(x)` | test if `x` is not `NA` `>=` | greater than or equal to ||`x %in% y` | test if `x` is in `y` `==` | exactly equal to ||`!(x %in% y)` | test if `x` is not in `y` `!=` | not equal to ||`!x` | not `x` `x & y` | `x` AND `y` || | --- ## `select` to keep variables ```r ncbikecrash %>% filter(county == "Durham", bike_age_group == "0-5") %>% select(locality, speed_limit) ``` ``` ## # A tibble: 4 x 2 ## locality speed_limit ## <chr> <chr> ## 1 Urban (>70% Developed) 30 - 35 MPH ## 2 Urban (>70% Developed) 5 - 15 MPH ## 3 Urban (>70% Developed) 20 - 25 MPH ## 4 Urban (>70% Developed) 20 - 25 MPH ``` --- ## `select` to exclude variables ```r ncbikecrash %>% select(-object_id) ``` ``` ## # A tibble: 7,467 x 65 ## city county region development locality on_road rural_urban speed_limit ## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 None… Wayne Coast… Farms, Woo… Rural (… SR 1915 Rural 50 - 55 M… ## 2 Hend… Vance Piedm… Residential Mixed (… NICHOL… Urban 30 - 35 M… ## 3 None… Linco… Piedm… Farms, Woo… Rural (… US 321 Rural 50 - 55 M… ## 4 Whit… Colum… Coast… Commercial Urban (… W BURK… Urban 30 - 35 M… ## 5 Wilm… New H… Coast… Residential Urban (… RACINE… Urban <NA> ## 6 None… Robes… Coast… Farms, Woo… Rural (… SR 1513 Rural 50 - 55 M… ## 7 None… Richm… Piedm… Residential Mixed (… SR 1903 Rural 30 - 35 M… ## 8 Rale… Wake Piedm… Commercial Urban (… PERSON… Urban 30 - 35 M… ## 9 Whit… Colum… Coast… Residential Rural (… FLOWER… Urban 30 - 35 M… ## 10 New … Craven Coast… Residential Urban (… SUTTON… Urban 20 - 25 M… ## # … with 7,457 more rows, and 57 more variables: traffic_control <chr>, ## # weather <chr>, workzone <chr>, bike_age <chr>, bike_age_group <chr>, ## # bike_alcohol <chr>, bike_alcohol_drugs <chr>, bike_direction <chr>, ## # bike_injury <chr>, bike_position <chr>, bike_race <chr>, ## # bike_sex <chr>, driver_age <chr>, driver_age_group <chr>, ## # driver_alcohol <chr>, driver_alcohol_drugs <chr>, ## # driver_est_speed <chr>, driver_injury <chr>, driver_race <chr>, ## # driver_sex <chr>, driver_vehicle_type <chr>, crash_alcohol <chr>, ## # crash_date <chr>, crash_day <chr>, crash_group <chr>, ## # crash_hour <int>, crash_location <chr>, crash_month <chr>, ## # crash_severity <chr>, crash_time <drtn>, crash_type <chr>, ## # crash_year <int>, ambulance_req <chr>, hit_run <chr>, ## # light_condition <chr>, road_character <chr>, road_class <chr>, ## # road_condition <chr>, road_configuration <chr>, road_defects <chr>, ## # road_feature <chr>, road_surface <chr>, num_bikes_ai <int>, ## # num_bikes_bi <int>, num_bikes_ci <int>, num_bikes_ki <int>, ## # num_bikes_no <int>, num_bikes_to <int>, num_bikes_ui <int>, ## # num_lanes <chr>, num_units <int>, distance_mi_from <chr>, ## # frm_road <chr>, rte_invd_cd <int>, towrd_road <chr>, geo_point <chr>, ## # geo_shape <chr> ``` --- ## `select` a range of variables ```r ncbikecrash %>% select(city:locality) ``` ``` ## # A tibble: 7,467 x 5 ## city county region development locality ## <chr> <chr> <chr> <chr> <chr> ## 1 None - Rural … Wayne Coastal Farms, Woods, Pa… Rural (<30% Develop… ## 2 Henderson Vance Piedmo… Residential Mixed (30% To 70% D… ## 3 None - Rural … Lincoln Piedmo… Farms, Woods, Pa… Rural (<30% Develop… ## 4 Whiteville Columbus Coastal Commercial Urban (>70% Develop… ## 5 Wilmington New Hanov… Coastal Residential Urban (>70% Develop… ## 6 None - Rural … Robeson Coastal Farms, Woods, Pa… Rural (<30% Develop… ## 7 None - Rural … Richmond Piedmo… Residential Mixed (30% To 70% D… ## 8 Raleigh Wake Piedmo… Commercial Urban (>70% Develop… ## 9 Whiteville Columbus Coastal Residential Rural (<30% Develop… ## 10 New Bern Craven Coastal Residential Urban (>70% Develop… ## # … with 7,457 more rows ``` --- ## `slice` for certain row numbers First five ```r ncbikecrash %>% slice(1:5) ``` ``` ## # A tibble: 5 x 66 ## object_id city county region development locality on_road rural_urban ## <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 1686 None… Wayne Coast… Farms, Woo… Rural (… SR 1915 Rural ## 2 1674 Hend… Vance Piedm… Residential Mixed (… NICHOL… Urban ## 3 1673 None… Linco… Piedm… Farms, Woo… Rural (… US 321 Rural ## 4 1687 Whit… Colum… Coast… Commercial Urban (… W BURK… Urban ## 5 1653 Wilm… New H… Coast… Residential Urban (… RACINE… Urban ## # … with 58 more variables: speed_limit <chr>, traffic_control <chr>, ## # weather <chr>, workzone <chr>, bike_age <chr>, bike_age_group <chr>, ## # bike_alcohol <chr>, bike_alcohol_drugs <chr>, bike_direction <chr>, ## # bike_injury <chr>, bike_position <chr>, bike_race <chr>, ## # bike_sex <chr>, driver_age <chr>, driver_age_group <chr>, ## # driver_alcohol <chr>, driver_alcohol_drugs <chr>, ## # driver_est_speed <chr>, driver_injury <chr>, driver_race <chr>, ## # driver_sex <chr>, driver_vehicle_type <chr>, crash_alcohol <chr>, ## # crash_date <chr>, crash_day <chr>, crash_group <chr>, ## # crash_hour <int>, crash_location <chr>, crash_month <chr>, ## # crash_severity <chr>, crash_time <drtn>, crash_type <chr>, ## # crash_year <int>, ambulance_req <chr>, hit_run <chr>, ## # light_condition <chr>, road_character <chr>, road_class <chr>, ## # road_condition <chr>, road_configuration <chr>, road_defects <chr>, ## # road_feature <chr>, road_surface <chr>, num_bikes_ai <int>, ## # num_bikes_bi <int>, num_bikes_ci <int>, num_bikes_ki <int>, ## # num_bikes_no <int>, num_bikes_to <int>, num_bikes_ui <int>, ## # num_lanes <chr>, num_units <int>, distance_mi_from <chr>, ## # frm_road <chr>, rte_invd_cd <int>, towrd_road <chr>, geo_point <chr>, ## # geo_shape <chr> ``` --- ## `slice` for certain row numbers Last five ```r last_row <- nrow(ncbikecrash) ncbikecrash %>% slice((last_row - 4):last_row) ``` ``` ## # A tibble: 5 x 66 ## object_id city county region development locality on_road rural_urban ## <int> <chr> <chr> <chr> <chr> <chr> <chr> <chr> ## 1 6989 High… Guilf… Piedm… Residential Urban (… <NA> Urban ## 2 6991 Wilm… New H… Coast… Residential Urban (… <NA> Urban ## 3 6995 Kins… Lenoir Coast… Commercial Urban (… <NA> Urban ## 4 6998 Faye… Cumbe… Coast… Residential Urban (… <NA> Urban ## 5 7000 None… Onslow Coast… Farms, Woo… Rural (… <NA> Rural ## # … with 58 more variables: speed_limit <chr>, traffic_control <chr>, ## # weather <chr>, workzone <chr>, bike_age <chr>, bike_age_group <chr>, ## # bike_alcohol <chr>, bike_alcohol_drugs <chr>, bike_direction <chr>, ## # bike_injury <chr>, bike_position <chr>, bike_race <chr>, ## # bike_sex <chr>, driver_age <chr>, driver_age_group <chr>, ## # driver_alcohol <chr>, driver_alcohol_drugs <chr>, ## # driver_est_speed <chr>, driver_injury <chr>, driver_race <chr>, ## # driver_sex <chr>, driver_vehicle_type <chr>, crash_alcohol <chr>, ## # crash_date <chr>, crash_day <chr>, crash_group <chr>, ## # crash_hour <int>, crash_location <chr>, crash_month <chr>, ## # crash_severity <chr>, crash_time <drtn>, crash_type <chr>, ## # crash_year <int>, ambulance_req <chr>, hit_run <chr>, ## # light_condition <chr>, road_character <chr>, road_class <chr>, ## # road_condition <chr>, road_configuration <chr>, road_defects <chr>, ## # road_feature <chr>, road_surface <chr>, num_bikes_ai <int>, ## # num_bikes_bi <int>, num_bikes_ci <int>, num_bikes_ki <int>, ## # num_bikes_no <int>, num_bikes_to <int>, num_bikes_ui <int>, ## # num_lanes <chr>, num_units <int>, distance_mi_from <chr>, ## # frm_road <chr>, rte_invd_cd <int>, towrd_road <chr>, geo_point <chr>, ## # geo_shape <chr> ``` --- ## `pull` to extract a column as a vector ```r ncbikecrash %>% slice(1:6) %>% pull(locality) ``` ``` ## [1] "Rural (<30% Developed)" "Mixed (30% To 70% Developed)" ## [3] "Rural (<30% Developed)" "Urban (>70% Developed)" ## [5] "Urban (>70% Developed)" "Rural (<30% Developed)" ``` vs. ```r ncbikecrash %>% slice(1:6) %>% select(locality) ``` ``` ## # A tibble: 6 x 1 ## locality ## <chr> ## 1 Rural (<30% Developed) ## 2 Mixed (30% To 70% Developed) ## 3 Rural (<30% Developed) ## 4 Urban (>70% Developed) ## 5 Urban (>70% Developed) ## 6 Rural (<30% Developed) ``` --- ## `sample_n` / `sample_frac` for a random sample - `sample_n`: randomly sample 5 observations ```r ncbikecrash_n5 <- ncbikecrash %>% sample_n(5, replace = FALSE) dim(ncbikecrash_n5) ``` ``` ## [1] 5 66 ``` - `sample_frac`: randomly sample 20% of observations ```r ncbikecrash_perc20 <-ncbikecrash %>% sample_frac(0.2, replace = FALSE) dim(ncbikecrash_perc20) ``` ``` ## [1] 1493 66 ``` --- ## `distinct` to filter for unique rows And `arrange` to order alphabetically ```r ncbikecrash %>% select(county, city) %>% distinct() %>% arrange(county, city) ``` ``` ## # A tibble: 391 x 2 ## county city ## <chr> <chr> ## 1 Alamance Alamance ## 2 Alamance Burlington ## 3 Alamance Elon ## 4 Alamance Elon College ## 5 Alamance Gibsonville ## 6 Alamance Graham ## 7 Alamance Green Level ## 8 Alamance Mebane ## 9 Alamance None - Rural Crash ## 10 Alexander None - Rural Crash ## # … with 381 more rows ``` --- ## `summarise` to reduce variables to values ```r ncbikecrash %>% summarise(avg_hr = mean(crash_hour)) ``` ``` ## # A tibble: 1 x 1 ## avg_hr ## <dbl> ## 1 14.7 ``` --- ## `group_by` to do calculations on groups ```r ncbikecrash %>% group_by(hit_run) %>% summarise(avg_hr = mean(crash_hour)) ``` ``` ## # A tibble: 2 x 2 ## hit_run avg_hr ## <chr> <dbl> ## 1 No 14.6 ## 2 Yes 15.0 ``` --- ## `count` observations in groups ```r ncbikecrash %>% count(driver_alcohol_drugs) ``` ``` ## # A tibble: 6 x 2 ## driver_alcohol_drugs n ## <chr> <int> ## 1 Missing 99 ## 2 No 695 ## 3 Yes-Alcohol, impairment suspected 12 ## 4 Yes-Alcohol, no impairment detected 3 ## 5 Yes-Drugs, impairment suspected 4 ## 6 <NA> 6654 ``` --- ## `mutate` to add new variables ```r ncbikecrash %>% mutate(driver_alcohol_drugs_simplified = case_when( driver_alcohol_drugs == "Missing" ~ NA, str_detect(driver_alcohol_drugs, "Yes") ~ "Yes", TRUE ~ "No" )) ``` --- ## "Save" when you `mutate` Most often when you define a new variable with `mutate` you'll also want to save the resulting data frame, often by writing over the original data frame. ```r ncbikecrash <- ncbikecrash %>% mutate(driver_alcohol_drugs_simplified = case_when( str_detect(driver_alcohol_drugs, "Yes") ~ "Yes", TRUE ~ driver_alcohol_drugs )) ``` --- ## Check before you move on ```r ncbikecrash %>% count(driver_alcohol_drugs, driver_alcohol_drugs_simplified) ``` ``` ## # A tibble: 6 x 3 ## driver_alcohol_drugs driver_alcohol_drugs_simplified n ## <chr> <chr> <int> ## 1 Missing Missing 99 ## 2 No No 695 ## 3 Yes-Alcohol, impairment suspected Yes 12 ## 4 Yes-Alcohol, no impairment detected Yes 3 ## 5 Yes-Drugs, impairment suspected Yes 4 ## 6 <NA> <NA> 6654 ``` ```r ncbikecrash %>% count(driver_alcohol_drugs_simplified) ``` ``` ## # A tibble: 4 x 2 ## driver_alcohol_drugs_simplified n ## <chr> <int> ## 1 Missing 99 ## 2 No 695 ## 3 Yes 19 ## 4 <NA> 6654 ``` --- ## <svg style="height:0.8em;top:.04em;position:relative;" viewBox="0 0 640 512"><path d="M512 64v256H128V64h384m16-64H112C85.5 0 64 21.5 64 48v288c0 26.5 21.5 48 48 48h416c26.5 0 48-21.5 48-48V48c0-26.5-21.5-48-48-48zm100 416H389.5c-3 0-5.5 2.1-5.9 5.1C381.2 436.3 368 448 352 448h-64c-16 0-29.2-11.7-31.6-26.9-.5-2.9-3-5.1-5.9-5.1H12c-6.6 0-12 5.4-12 12v36c0 26.5 21.5 48 48 48h544c26.5 0 48-21.5 48-48v-36c0-6.6-5.4-12-12-12z"/></svg> AE - NC bike crashes - Go to the cloud project and open application exercise NC bike crashes ~appex/ae-ncbikecrashes.Rmd - For each question you work on, set the `eval` chunk option to `TRUE` and knit --- class: title-slide name: coding # Coding style <br> 🤵 --- class: center, middle # Coding style --- ## Style guide >Good coding style is like correct punctuation: you can manage without it, butitsuremakesthingseasiertoread. > >Hadley Wickham - Style guide for this course is based on the Tidyverse style guide: http://style.tidyverse.org/ - There's more to it than what we'll cover today, but we'll mention more as we introduce more functionality, and do a recap later in the semester --- ## File names and code chunk labels - Do not use spaces in file names, use `-` or `_` to separate words - Use all lowercase letters ```r # Good ucb-admit.csv # Bad UCB Admit.csv ``` --- ## Object names - Use `_` to separate words in object names - Use informative but short object names - Do not reuse object names within an analysis ```r # Good acs_employed # Bad acs.employed acs2 acs_subset acs_subsetted_for_males ``` --- <img src="img/meaningful-variable-name.jpg" height="50%" style="display: block; margin: auto;" /> --- ## Spacing - Put a space before and after all infix operators (=, +, -, <-, etc.), and when naming arguments in function calls. - Always put a space after a comma, and never before (just like in regular English). ```r # Good average <- mean(feet / 12 + inches, na.rm = TRUE) # Bad average<-mean(feet/12+inches,na.rm=TRUE) ``` --- ## ggplot - Always end a line with `+` - Always indent the next line ```r # Good ggplot(diamonds, mapping = aes(x = price)) + geom_histogram() # Bad ggplot(diamonds,mapping=aes(x=price))+geom_histogram() ``` --- ## Long lines - Limit your code to 80 characters per line. This fits comfortably on a printed page with a reasonably sized font. - Take advantage of RStudio editor's auto formatting for indentation at line breaks. --- ## Assignment - Use `<-` not `=` ```r # Good x <- 2 # Bad x = 2 ``` -- <img src="img/assign.jpg" style="display: block; margin: auto;" /> --- ## Quotes Use `"`, not `'`, for quoting text. The only exception is when the text already contains double quotes and no single quotes. ```r ggplot(diamonds, mapping = aes(x = price)) + geom_histogram() + # Good labs(title = "`Shine bright like a diamond`", # Good x = "Diamond prices", # Bad y = 'Frequency') ``` --- class: title-slide name: types # Data classes and types + Recoding <br> 💽 --- class: center, middle # Data classes and types --- ## Data types in R * **logical** * **double** * **integer** * **character** * **lists** * and some more, but we won't be focusing on those --- ## Logical & character **logical** - boolean values `TRUE` and `FALSE` ```r typeof(TRUE) ``` ``` ## [1] "logical" ``` **character** - character strings ```r typeof("hello") ``` ``` ## [1] "character" ``` ```r typeof('world') # but remember, we use double quotations! ``` ``` ## [1] "character" ``` --- ## Double & integer **double** - floating point numerical values (default numerical type) ```r typeof(1.335) ``` ``` ## [1] "double" ``` ```r typeof(7) ``` ``` ## [1] "double" ``` **integer** - integer numerical values (indicated with an `L`) ```r typeof(7L) ``` ``` ## [1] "integer" ``` ```r typeof(1:3) ``` ``` ## [1] "integer" ``` --- ## Lists **Lists** are 1d objects that can contain any combination of R objects .small[ ```r mylist <- list("A", 1:4, c(TRUE, FALSE), (1:4)/2) mylist ``` ``` ## [[1]] ## [1] "A" ## ## [[2]] ## [1] 1 2 3 4 ## ## [[3]] ## [1] TRUE FALSE ## ## [[4]] ## [1] 0.5 1.0 1.5 2.0 ``` ```r str(mylist) ``` ``` ## List of 4 ## $ : chr "A" ## $ : int [1:4] 1 2 3 4 ## $ : logi [1:2] TRUE FALSE ## $ : num [1:4] 0.5 1 1.5 2 ``` ] --- ## Named lists Because of their more complex structure we often want to name the elements of a list (we can also do this with vectors). This can make reading and accessing the list more straight forward. .small[ ```r myotherlist <- list(A = "hello", B = 1:4, "knock knock" = "who's there?") str(myotherlist) ``` ``` ## List of 3 ## $ A : chr "hello" ## $ B : int [1:4] 1 2 3 4 ## $ knock knock: chr "who's there?" ``` ```r names(myotherlist) ``` ``` ## [1] "A" "B" "knock knock" ``` ```r myotherlist$B ``` ``` ## [1] 1 2 3 4 ``` ] --- ## Concatenation Vectors can be constructed using the `c()` function. ```r c(1, 2, 3) ``` ``` ## [1] 1 2 3 ``` ```r c("Hello", "World!") ``` ``` ## [1] "Hello" "World!" ``` ```r c(1, c(2, c(3))) ``` ``` ## [1] 1 2 3 ``` --- ## Coercion R is a dynamically typed language -- it will happily convert between the various types without complaint. ```r c(1, "Hello") ``` ``` ## [1] "1" "Hello" ``` ```r c(FALSE, 3L) ``` ``` ## [1] 0 3 ``` ```r c(1.2, 3L) ``` ``` ## [1] 1.2 3.0 ``` --- ## Missing Values R uses `NA` to represent missing values in its data structures. ```r typeof(NA) ``` ``` ## [1] "logical" ``` --- ## Other Special Values `NaN` - Not a number `Inf` - Positive infinity `-Inf` - Negative infinity <br/> .pull-left[ ```r pi / 0 ``` ``` ## [1] Inf ``` ```r 0 / 0 ``` ``` ## [1] NaN ``` ```r 1/0 + 1/0 ``` ``` ## [1] Inf ``` ] .pull-right[ ```r 1/0 - 1/0 ``` ``` ## [1] NaN ``` ```r NaN / NA ``` ``` ## [1] NaN ``` ```r NaN * NA ``` ``` ## [1] NaN ``` ] --- ## Activity .question[ What is the type of the following vectors? Explain why they have that type. ] * `c(1, NA+1L, "C")` * `c(1L / 0, NA)` * `c(1:3, 5)` * `c(3L, NaN+1L)` * `c(NA, TRUE)` --- ## Example: Cat lovers Go to RStudio Cloud and open the application exercise Cat Lovers. ~/appex/ae-catlovers.Rmd A survey asked respondents their name and number of cats. The instructions said to enter the number of cats as a numerical value. .small[ ```r cat_lovers <- read_csv("../data/cat-lovers.csv") ``` <div id="htmlwidget-107a8027c1425232b046" style="width:100%;height:auto;" class="datatables html-widget"></div> <script type="application/json" data-for="htmlwidget-107a8027c1425232b046">{"x":{"filter":"none","data":[["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31","32","33","34","35","36","37","38","39","40","41","42","43","44","45","46","47","48","49","50","51","52","53","54","55","56","57","58","59","60"],["Bernice Warren","Woodrow Stone","Willie Bass","Tyrone Estrada","Alex Daniels","Jane Bates","Latoya Simpson","Darin Woods","Agnes Cobb","Tabitha Grant","Perry Cross","Wanda Silva","Alicia Sims","Emily Logan","Woodrow Elliott","Brent Copeland","Pedro Carlson","Patsy Luna","Brett Robbins","Oliver George","Calvin Perry","Lora Gutierrez","Charlotte Sparks","Earl Mack","Leslie Wade","Santiago Barker","Jose Bell","Lynda Smith","Bradford Marshall","Irving Miller","Caroline Simpson","Frances Welch","Melba Jenkins","Veronica Morales","Juanita Cunningham","Maurice Howard","Teri Pierce","Phil Franklin","Jan Zimmerman","Leslie Price","Bessie Patterson","Ethel Wolfe","Naomi Wright","Sadie Frank","Lonnie Cannon","Tony Garcia","Darla Newton","Ginger Clark","Lionel Campbell","Florence Klein","Harriet Leonard","Terrence Harrington","Travis Garner","Doug Bass","Pat Norris","Dawn Young","Shari Alvarez","Tamara Robinson","Megan Morgan","Kara Obrien"],["0","0","1","3","3","2","1","1","0","0","0","0","1","3","3","2","1","1","0","0","1","1","0","0","4","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","1","3","3","2","1","1.5 - honestly I think one of my cats is half human","0","0","0","0","1","three","1","1","1","0","0","2"],["left","left","left","left","left","left","left","left","left","left","left","left","left","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","ambidextrous","ambidextrous","ambidextrous","ambidextrous","ambidextrous"]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>name<\/th>\n <th>number_of_cats<\/th>\n <th>handedness<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"order":[],"autoWidth":false,"orderClasses":false,"columnDefs":[{"orderable":false,"targets":0}]}},"evals":[],"jsHooks":[]}</script> ] --- ## Oh why won't you work?! ```r cat_lovers %>% summarise(mean = mean(number_of_cats)) ``` ``` ## # A tibble: 1 x 1 ## mean ## <dbl> ## 1 NA ``` --- ## Oh why won't you still work??!! ```r cat_lovers %>% summarise(mean_cats = mean(number_of_cats, na.rm = TRUE)) ``` ``` ## # A tibble: 1 x 1 ## mean_cats ## <dbl> ## 1 NA ``` --- ## Take a breath and look at your data .question[ What is the type of the `number_of_cats` variable? ] ```r glimpse(cat_lovers) ``` ``` ## Observations: 60 ## Variables: 3 ## $ name <chr> "Bernice Warren", "Woodrow Stone", "Willie Bass",… ## $ number_of_cats <chr> "0", "0", "1", "3", "3", "2", "1", "1", "0", "0",… ## $ handedness <chr> "left", "left", "left", "left", "left", "left", "… ``` --- ## Let's take another look .small[ <div id="htmlwidget-511f913b47a8a228a95d" style="width:100%;height:auto;" class="datatables html-widget"></div> <script type="application/json" data-for="htmlwidget-511f913b47a8a228a95d">{"x":{"filter":"none","data":[["1","2","3","4","5","6","7","8","9","10","11","12","13","14","15","16","17","18","19","20","21","22","23","24","25","26","27","28","29","30","31","32","33","34","35","36","37","38","39","40","41","42","43","44","45","46","47","48","49","50","51","52","53","54","55","56","57","58","59","60"],["Bernice Warren","Woodrow Stone","Willie Bass","Tyrone Estrada","Alex Daniels","Jane Bates","Latoya Simpson","Darin Woods","Agnes Cobb","Tabitha Grant","Perry Cross","Wanda Silva","Alicia Sims","Emily Logan","Woodrow Elliott","Brent Copeland","Pedro Carlson","Patsy Luna","Brett Robbins","Oliver George","Calvin Perry","Lora Gutierrez","Charlotte Sparks","Earl Mack","Leslie Wade","Santiago Barker","Jose Bell","Lynda Smith","Bradford Marshall","Irving Miller","Caroline Simpson","Frances Welch","Melba Jenkins","Veronica Morales","Juanita Cunningham","Maurice Howard","Teri Pierce","Phil Franklin","Jan Zimmerman","Leslie Price","Bessie Patterson","Ethel Wolfe","Naomi Wright","Sadie Frank","Lonnie Cannon","Tony Garcia","Darla Newton","Ginger Clark","Lionel Campbell","Florence Klein","Harriet Leonard","Terrence Harrington","Travis Garner","Doug Bass","Pat Norris","Dawn Young","Shari Alvarez","Tamara Robinson","Megan Morgan","Kara Obrien"],["0","0","1","3","3","2","1","1","0","0","0","0","1","3","3","2","1","1","0","0","1","1","0","0","4","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","0","1","3","3","2","1","1.5 - honestly I think one of my cats is half human","0","0","0","0","1","three","1","1","1","0","0","2"],["left","left","left","left","left","left","left","left","left","left","left","left","left","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","right","ambidextrous","ambidextrous","ambidextrous","ambidextrous","ambidextrous"]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>name<\/th>\n <th>number_of_cats<\/th>\n <th>handedness<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"order":[],"autoWidth":false,"orderClasses":false,"columnDefs":[{"orderable":false,"targets":0}]}},"evals":[],"jsHooks":[]}</script> ] --- ## Sometimes you need to babysit your respondents ```r cat_lovers %>% mutate(number_of_cats = case_when( name == "Ginger Clark" ~ 2, name == "Doug Bass" ~ 3, TRUE ~ as.numeric(number_of_cats) )) %>% summarise(mean_cats = mean(number_of_cats)) ``` ``` ## # A tibble: 1 x 1 ## mean_cats ## <dbl> ## 1 0.817 ``` --- ## Always you need to respect data types ```r cat_lovers %>% mutate( number_of_cats = case_when( name == "Ginger Clark" ~ "2", name == "Doug Bass" ~ "3", TRUE ~ number_of_cats ), number_of_cats = as.numeric(number_of_cats) ) %>% summarise(mean_cats = mean(number_of_cats)) ``` ``` ## # A tibble: 1 x 1 ## mean_cats ## <dbl> ## 1 0.817 ``` --- ## Now that we know what we're doing... ```r cat_lovers <- cat_lovers %>% mutate( number_of_cats = case_when( name == "Ginger Clark" ~ "2", name == "Doug Bass" ~ "3", TRUE ~ number_of_cats ), number_of_cats = as.numeric(number_of_cats) ) ``` --- ## Moral of the story - If your data does not behave how you expect it to, type coercion upon reading in the data might be the reason. - Go in and investigate your data, apply the fix, *save your data*, live happily ever after. --- ## Vectors vs. lists .pull-left[ .small[ ```r x <- c(8,4,7) ``` ] .small[ ```r x[1] ``` ``` ## [1] 8 ``` ] .small[ ```r x[[1]] ``` ``` ## [1] 8 ``` ] ] -- .pull-right[ .small[ ```r y <- list(8,4,7) ``` ] .small[ ```r y[2] ``` ``` ## [[1]] ## [1] 4 ``` ] .small[ ```r y[[2]] ``` ``` ## [1] 4 ``` ] ] -- <br> **Note:** When using tidyverse code you'll rarely need to refer to elements using square brackets, but it's good to be aware of this syntax, especially since you might encounter it when searching for help online. --- class: center, middle # Review on your own --- class: center, middle name: datasets # Data "set" --- ## Data "sets" in R - "set" is in quotation marks because it is not a formal data class - A tidy data "set" can be one of the following types: + `tibble` + `data.frame` - We'll often work with `tibble`s: + `readr` package (e.g. `read_csv` function) loads data as a `tibble` by default + `tibble`s are part of the tidyverse, so they work well with other packages we are using + they make minimal assumptions about your data, so are less likely to cause hard to track bugs in your code --- ## Data frames - A data frame is the most commonly used data structure in R, they are just a list of equal length vectors (usually atomic, but you can use generic as well). Each vector is treated as a column and elements of the vectors as rows. - A tibble is a type of data frame that ... makes your life (i.e. data analysis) easier. - Most often a data frame will be constructed by reading in from a file, but we can also create them from scratch. ```r df <- tibble(x = 1:3, y = c("a", "b", "c")) class(df) ``` ``` ## [1] "tbl_df" "tbl" "data.frame" ``` ```r glimpse(df) ``` ``` ## Observations: 3 ## Variables: 2 ## $ x <int> 1, 2, 3 ## $ y <chr> "a", "b", "c" ``` --- ## Data frames (cont.) ```r attributes(df) ``` ``` ## $names ## [1] "x" "y" ## ## $row.names ## [1] 1 2 3 ## ## $class ## [1] "tbl_df" "tbl" "data.frame" ``` ```r class(df$x) ``` ``` ## [1] "integer" ``` ```r class(df$y) ``` ``` ## [1] "character" ``` --- ## Working with tibbles in pipelines .question[ How many respondents have below average number of cats? ] ```r mean_cats <- cat_lovers %>% summarise(mean_cats = mean(number_of_cats)) cat_lovers %>% filter(number_of_cats < mean_cats) %>% nrow() ``` ``` ## [1] 60 ``` .question[ Do you believe this number? Why, why not? ] --- ## A result of a pipeline is always a tibble ```r mean_cats ``` ``` ## # A tibble: 1 x 1 ## mean_cats ## <dbl> ## 1 0.817 ``` ```r class(mean_cats) ``` ``` ## [1] "tbl_df" "tbl" "data.frame" ``` --- ## `pull()` can be your new best friend But use it sparingly! ```r mean_cats <- cat_lovers %>% summarise(mean_cats = mean(number_of_cats)) %>% pull() cat_lovers %>% filter(number_of_cats < mean_cats) %>% nrow() ``` ``` ## [1] 33 ``` -- ```r mean_cats ``` ``` ## [1] 0.8166667 ``` ```r class(mean_cats) ``` ``` ## [1] "numeric" ``` --- class: center, middle name: factors # Factors --- ## Factors Factor objects are how R stores data for categorical variables (fixed numbers of discrete values). ```r (x = factor(c("BS", "MS", "PhD", "MS"))) ``` ``` ## [1] BS MS PhD MS ## Levels: BS MS PhD ``` ```r glimpse(x) ``` ``` ## Factor w/ 3 levels "BS","MS","PhD": 1 2 3 2 ``` ```r typeof(x) ``` ``` ## [1] "integer" ``` --- ## Read data in as character strings ```r glimpse(cat_lovers) ``` ``` ## Observations: 60 ## Variables: 3 ## $ name <chr> "Bernice Warren", "Woodrow Stone", "Willie Bass",… ## $ number_of_cats <dbl> 0, 0, 1, 3, 3, 2, 1, 1, 0, 0, 0, 0, 1, 3, 3, 2, 1… ## $ handedness <chr> "left", "left", "left", "left", "left", "left", "… ``` --- ## But coerce when plotting ```r p <- ggplot(cat_lovers, mapping = aes(x = handedness)) + geom_bar() p ``` <img src="index_files/figure-html/unnamed-chunk-84-1.png" width="504" /> --- ## Use forcats to manipulate factors ```r cat_lovers <- cat_lovers %>% mutate(handedness = fct_relevel(handedness, "right", "left", "ambidextrous")) ``` ```r p <- ggplot(cat_lovers, mapping = aes(x = handedness)) + geom_bar() p ``` <img src="index_files/figure-html/unnamed-chunk-86-1.png" width="504" /> --- ## Come for the functionality .pull-left[ ... stay for the logo ] .pull-right[  ] - R uses factors to handle categorical variables, variables that have a fixed and known set of possible values. Historically, factors were much easier to work with than character vectors, so many base R functions automatically convert character vectors to factors. - However, factors are still useful when you have true categorical data, and when you want to override the ordering of character vectors to improve display. The goal of the forcats package is to provide a suite of useful tools that solve common problems with factors. .footnote[ Source: [forcats.tidyverse.org](http://forcats.tidyverse.org/) ] --- ## Recap - Always best to think of data as part of a tibble + This plays nicely with the `tidyverse` as well + Rows are observations, columns are variables - Be careful about data types / classes + Sometimes `R` makes silly assumptions about your data class + Using `tibble`s help, but it might not solve all issues + Think about your data in context, e.g. 0/1 variable is most likely a `factor` + If a plot/output is not behaving the way you expect, first investigate the data class + If you are absolutely sure of a data class, overwrite it in your tibble so that you don't need to keep having to keep track of it + `mutate` the variable with the correct class - Check out Alison Hill's "Working with Data in R" `saved in the R folder of the RStudio project` --- class: title-slide name: resources # Resources --- ## Online Books [R for Data Science](https://r4ds.had.co.nz/) >This book will teach you how to do data science with R: You’ll learn how to get your data into R, get it into the most useful structure, transform it, visualise it and model it. > [ModernDive: Statistical Inference via Data Science](https://moderndive.com/index.html) >This is intended to be a gentle introduction to the practice of analyzing data and answering questions using data the way data scientists, statisticians, data journalists, and other researchers would. > [Data Visualization: A practical Introduction](https://socviz.co/) >This book is a hands-on introduction to the principles and practice of looking at and presenting data using R and ggplot. > [Fundamentals of Data Visualization](https://serialmentor.com/dataviz/) >The book is meant as a guide to making visualizations that accurately reflect the data, tell a story, and look professional. Even though nearly all of the figures in this book were made with R and ggplot2, this is not an R book. It focuses on the concepts and the figures, not on the code. > ## Open source R-based Courses *Alison Hill* - [Introduction to Biostatistics for the Basic Sciences](https://ohsu-conj620.netlify.com/index.html) - Oregon Health & Science University *Mine Cetinkaya-Rundel* - [Intro to Data Science](http://www2.stat.duke.edu/courses/Spring18/Sta199/) - Duke --- name: index These links will take you to each relevant section in the presentation - [Home](https://cih-briefr.netlify.com/#1) - [Tidy Data](https://cih-briefr.netlify.com/#tidy) - [Data Wrangling](https://cih-briefr.netlify.com/#wrangle) - [Coding Style](https://cih-briefr.netlify.com/#coding) - [Datasets in R](https://cih-briefr.netlify.com/#datasets) - [Dealing with Factors](https://cih-briefr.netlify.com/#factors) - [Index](https://cih-briefr.netlify.com/#index) - [Memes](https://cih-briefr.netlify.com/#memes) --- class: title-slide name: memes # Who wants to make a meme? <br> ☝️ --- ## Welcome to the `memer` package 📦 ```r remotes::install_github("sctyner/memer") library(memer) ``` >[memer](https://sctyner.github.io/memer/index.html) is a a `tidyverse`-compatible R package for creating memes > -- ```r meme_get("OprahGiveaway") %>% meme_text_bottom("EVERYONE GETS A MEME!", size = 30) ``` <img src="img/oprah.png" style="display: block; margin: auto;" /> --- ## What's in the package? ```r meme_list() ``` ``` ## [1] "AllTheThings" "AmericanChopper" "AncientAliens" ## [4] "BatmanRobin" "DistractedBf" "EvilKermit" ## [7] "ExpandingBrain" "FirstWorldProbs" "FryNotSure" ## [10] "HotlineDrake" "IsThisAPigeon" "NoneOfMyBusiness" ## [13] "CheersLeo" "OneDoesNotSimply" "DosEquisMan" ## [16] "OffRamp" "OprahGiveaway" "Philosoraptor" ## [19] "PicardFacePalm" "PicardWTH" "Purples" ## [22] "PutItPatrick" "Rainbow" "ShiaJustDoIt" ## [25] "Spongebob" "SuccessKid" "ThatWouldBeGreat" ## [28] "TheRockDriving" "ThinkAboutIt" "TrumpBillSigning" ## [31] "TwoButtonsAnxiety" "WhatIfIToldYou" "CondescendingWonka" ## [34] "YoDawg" "Y-U-NOguy" ``` --- ## Let's make a meme -- ```r meme_get("TheRockDriving") %>% meme_text_rock("Hey, how do I prep for an IRB audit?", "\nPrint, \n...everything.") ``` <img src="img/rock.png" style="display: block; margin: auto;" /> --- ## Now you try ```r meme_get("SuccessKid") %>% meme_text_bottom("ENTER TEXT HERE") ``` --- class: title-slide name: coffee # Coffee Time .center[  ] ## Can't touch this --- class: center, middle name: maybe <img src="img/maybe.jpg" style="display: block; margin: auto;" />